성능을 비교해가며 인덱스 적용하기
들어가며
데이터베이스 인덱스 말만 들어보았지 제대로 적용해 본 적이 없는 것 같아 제대로 배우고 개인적으로 운영 중인 프로젝트에 적용해보기 위해 index 적용전 , 적용 후 비교를 해보며 어떻게 인덱스를 설정하면 좋을지 탐구해보았다.
인덱스란?
먼저 인덱스에 대해서 알아보면 서점에 갔을 때 수많은 책들 중에서 내가 원하는 책을 찾기 위해 카테고리를 먼저 보고 찾아가는 과정이 인덱스의 핵심적인 개념과 일치한다.
인덱스는 추가적인 저장공간을 이용해서 테이블 검색 속도를 향상하기 위한 자료구조이다. 인덱스에는 키와 키에 대한 데이터 저장공간의 물리적인 위치가 있다.
인덱스는 왜 사용할까?
인덱스는 키 값에 대해 데이터의 물리적인 위치만 가지고 있기 때문에 우리가 알고 있는 데이터베이스 테이블보다 크기가 월등히 작다. 테이블의 크기가 클수록 원하는 데이터를 찾기 위해서는 더욱 오래 걸리게 되는데 인덱스는 필요한 정보만 메모리에 적재하고 필요한 정보의 물리적 주소만 찾아 최소한의 I/O 만 발생하기 때문에 인덱스를 사용한다.
인덱스의 자료구조
인덱스로 얻는 이점을 탐구하기위해서는 인덱스가 어떻게 생겼는지 , 어떤 자료구조를 가지고 동작하는지를 알아야 한다. 단일 탐색은 빠르지만 범위 탐색에서 불리한 해시 테이블 , 조회 성능이 월등하지만 삽입 , 삭제 , 수정에는 취약한 정렬된 리스트보다는 균형을 가진 트리가 유리하다. 균형 트리는 트리구조를 가지며 트리가 한쪽으로 쏠리지 않게 균형을 유지하는 트리를 말한다. 대표적으로 레드블랙트리 , B+Tree 가 있고 여기서 중요한 것은 균형 트리의 높이가 낮을수록 원하는 데이터를 빠르게 찾을 수 있다.
내가 이용할 MySQL(InnoDB 엔진) 은 B+Tree 를 이용하는데 B+Tree 는 리프 노드의 키만 데이터 포인터를 가지고 있다. 이는 하나의 노드에 키에 대한 정보를 더 많이 보관할 수 있음을 의미하고 이는 더 낮은 트리를 유지할 수 있다는 의미로도 이어진다. 뿐만 아니라 리프 노드끼리 연결리스트로 연결되어 있기 때문에 순차 검색에 유리하다. 하지만 노드에 키값과 데이터 포인터를 가지고 있는 B-Tree 와는 다르게 리프노드에만 데이터 포인터를 가지고 있으므로 항상 리프노드 까지 탐색을 해야 한다는 단점을 가지고 있다.
MySQL 은 PK 가 아닌 인덱스인 경우 실제 데이터에 대한 물리적인 위치를 가지고 있는 것이 아니라 PK에 대한 정보를 가지고 있다. MySQL 은 PK를 클러스터 인덱스로 가지고 있기 때문이다.
인덱스도 결국 트레이드 오프
인덱스 정보를 유지하기 위해서 테이블에 쓰기가 발생했을 때 B+Tree 가 재구성되어야 한다. 이는 조회를 얻는 대신 쓰기 공간과 쓰기 작업을 희생한 것이다. 또한 인덱스로 탐색 범위를 충분히 좁힐 수 없는 경우에는 인덱스를 생성하지 않은 것만 못할 수 있기 때문에 인덱스를 설정할 때 탐구가 필요하다.
인덱스를 적용할 프로젝트 개요
- 서비스 허브에는 웹 서비스에 대한 정보가 존재하고 Services 테이블로 관리한다.
- 사용자는 서비스 허브에 있는 웹 서비스를 이용하고 있는 정보를 나타내는 관계 테이블이 존재하고 이를 Customer_Service 테이블로 관리한다.
- 사용자는 서비스 허브에는 없지만 자신이 이용하고 있는 서비스를 저장할 수 있고 이 정보는 Custom_Service 테이블에 기록되고 관리한다.
- Schema 정보 (Customer 사용자 정보는 Id 로만 관리됩니다.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
create table services
(
service_id bigint not null auto_increment,
created_at date not null,
created_by varchar(255) not null,
modified_by varchar(255),
updated_at date not null,
content TEXT not null,
logo_store_name varchar(255),
service_name varchar(255) not null UNIQUE,
service_url varchar(255) not null UNIQUE,
title varchar(255),
primary key (service_id)
) engine = InnoDB;
create table custom_service
(
custom_service_id bigint not null auto_increment,
customer_id bigint not null,
....
primary key (custom_service_id)
) engine = InnoDB;
create table customer_service
(
customer_service_id bigint not null auto_increment,
service_id bigint not null,
customer_id bigint not null,
...
FOREIGN KEY (service_id) references services (service_id),
primary key (customer_service_id)
) engine = InnoDB;
- ERD 정보
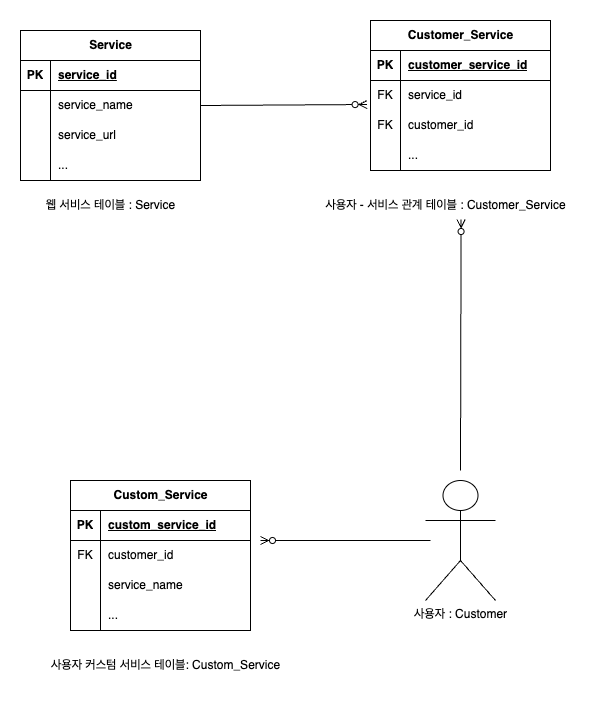
정리하면 사용자는 서비스 허브에 등록된 서비스를 북마크 처럼 추가할 수 있으며 그 관계가 Customer_service 에 저장된다. 또한 사용자는 자신만 이용할 수 있는 커스텀 서비스를 등록할 수 있는데 이는 Custom_Service 에 저장된다.
충분한 데이터 셋 확보하기
- 서비스 테이블 : 10만개
- 사용자 수 : 1만명
- 사용자마다 추가한 서비스의 평균 : 100개
- 사용자마다 추가한 커스텀 서비스의 평균 : 100개

- 사용자 수가 1만명이고 사용자마다 추가한 서비스 수가 100개이므로 총 100만 레코드
- 사용자 수가 1만명이고 사용자마다 추가한 커스텀 서비스 수가 100개이므로 총 100만 레코드
커스텀 서비스 조회 쿼리 분석하기
커스텀 서비스의 조회 쿼리는 크게 두가지가 있다.
- 사용자 아이디인
customer_id로 사용자가 추가한 커스텀 서비스 조회 - 사용자 아디디인
customer_id와ServiceName으로 사용자가 추가한 커스텀 서비스 조회
사용자 아이디인 customer_id 로 사용자가 추가한 커스텀서비스 조회
쿼리
1
2
3
SELECT *
FROM CUSTOM_SERVICE as cs
WHERE cs.customer_id = 9000;
인덱스 없이 조회하기
1
2
3
EXPLAIN SELECT *
FROM CUSTOM_SERVICE as cs
WHERE cs.customer_id = 9000;
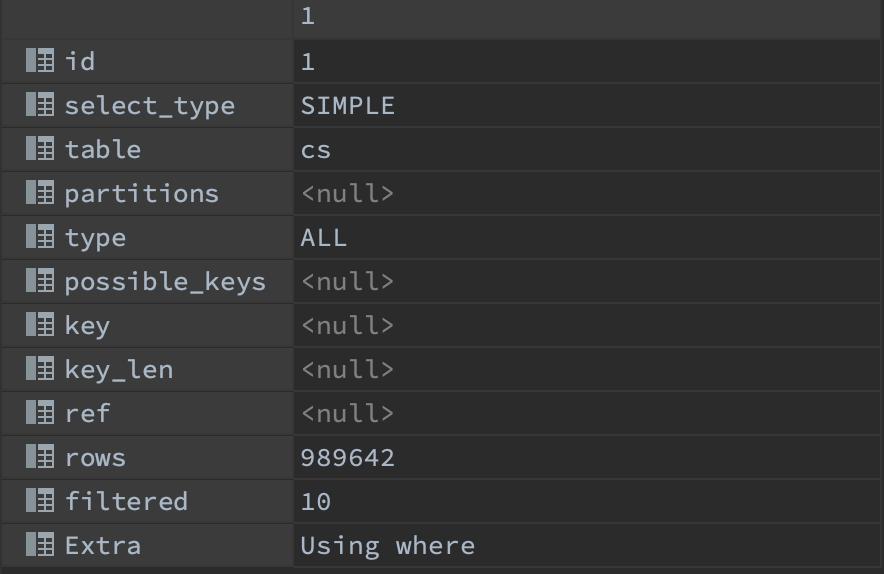 explain 키워드를 통해 실행 계획을 확인해볼 수 있는데
explain 키워드를 통해 실행 계획을 확인해볼 수 있는데 rows = 989642를 보면 해당 쿼리에 대한 결과를 가져오기위해 테이블을 모두 보았다고 볼 수 있다. type 값이 ALL 인 경우 Table Full Scan을 의미한다. 실제로 수행시간은 681 ms 가 소요된다.
customer_id 인덱스를 생성하고 조회하기
1
CREATE INDEX CUSTOMER_ID_INDEX ON CUSTOM_SERVICE(customer_id); # 인덱스 생성
1
2
3
EXPLAIN SELECT *
FROM CUSTOM_SERVICE as cs USE INDEX(CUSTOMER_ID_INDEX) # customer_id index 힌트
WHERE cs.customer_id = 9000;
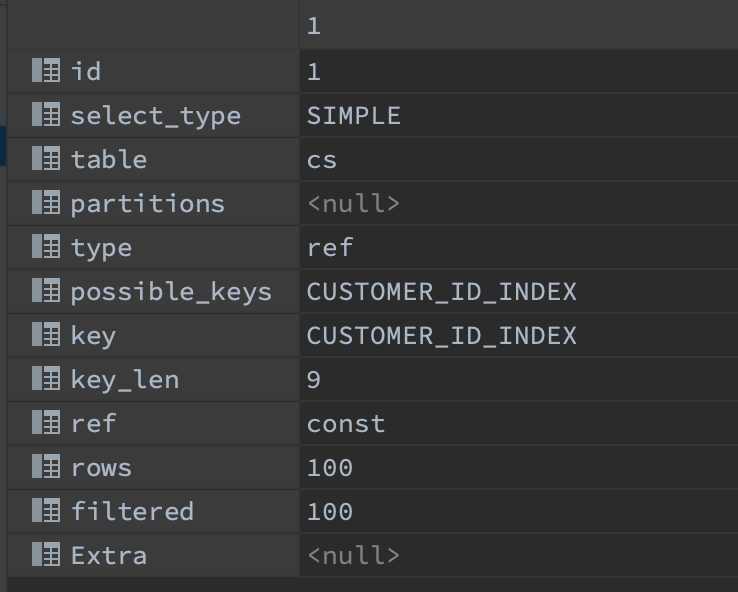
여기서는 type 값이 ref 임을 확인할 수 있는데 이는 고유키가 아닌 인덱스에 대한 비교를 수행했다는 것을 의미하고 rows = 100 으로 customer_id 에 대해 100개의 레코드만을 가지기 때문에 100 개 레코드만을 확인한 것을 알 수 있다. 실제로 수행시간은 76 ms 으로 인덱스를 적용하지 않았을 때보다 약 10배 빨라졌다고 할 수 있다.
옵티마이저
인덱스 힌트 없이는 CUSTOMER_ID_INDEX 를 사용하여 쿼리를 실행한다.하지만 매번 옳은 결정을 하는 것이 아니니 항상 테스트를 진행해보아야한다.
성능 비교
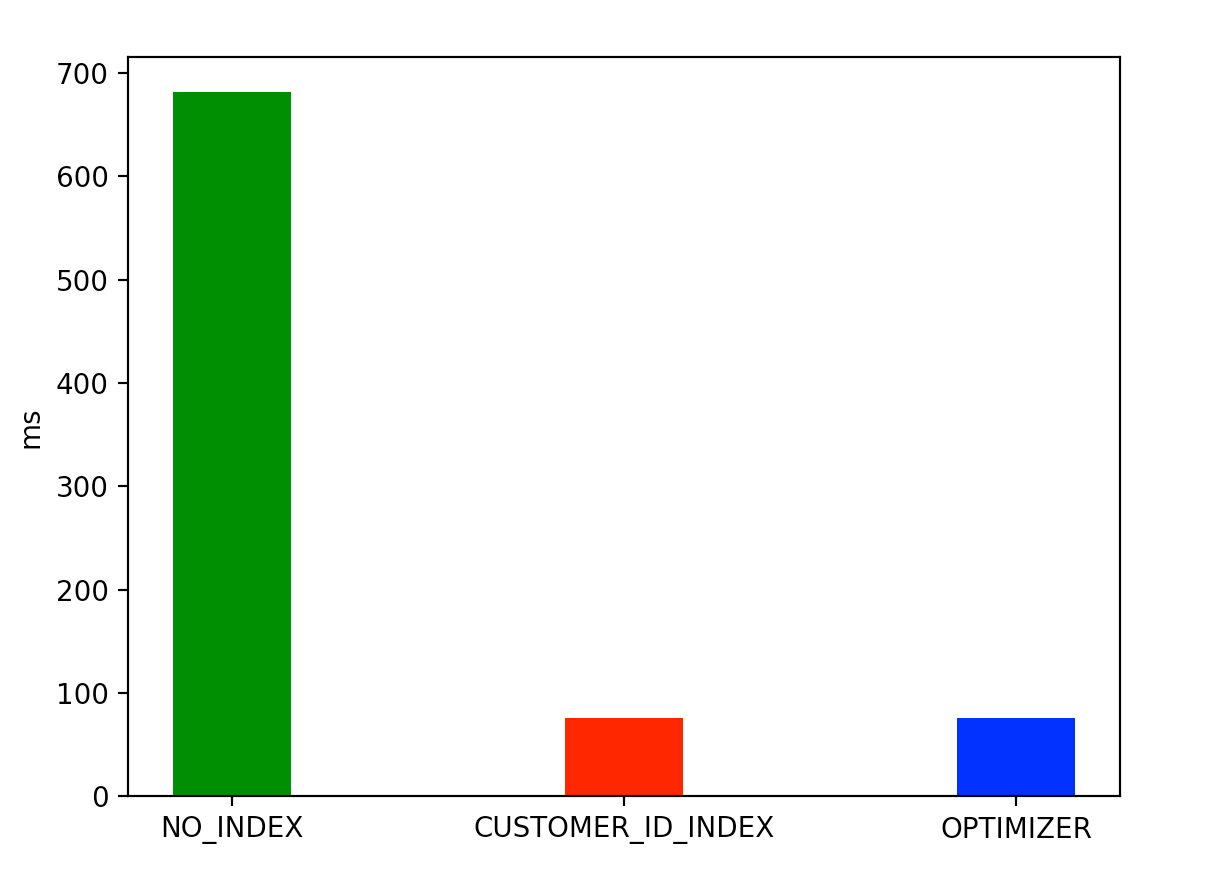
customer_id 와 ServiceName 으로 사용자가 추가한 커스텀 서비스 조회
쿼리
1
2
3
SELECT *
FROM CUSTOM_SERVICE as cs
WHERE cs.customer_id = 9000 AND cs.service_name like '%:serviceName%';
인덱스 없이 조회하기
type 값이 ALL 로 테이블 풀 스캔을 통해 결과를 조회한다. 694 ms 소요.
1
2
3
SELECT *
FROM CUSTOM_SERVICE as cs
WHERE cs.customer_id = 9000 AND cs.service_name like '%:serviceName%';
customer_id 인덱스 사용
1
2
3
SELECT *
FROM CUSTOM_SERVICE as cs USE INDEX(CUSTOMER_ID_INDEX)
WHERE cs.customer_id = 9000 AND cs.service_name like '%:serviceName%';
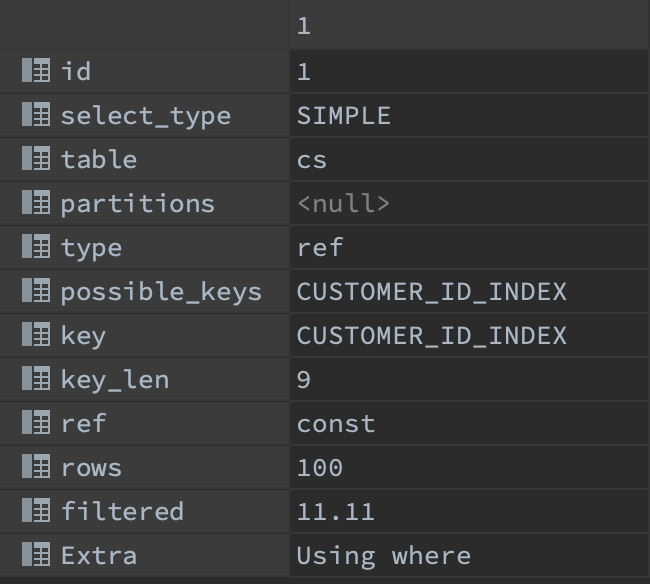
type 값이 ref , rows = 100 으로 만족하는 customer_id 에 대해 행을 가져온 뒤 cs.service_name like '%f%' 을 통해 최종적인 결과를 가져온 것을 확인할 수 있다. 66 ms 소요.
customer_id ,service_name 복합 인덱스 사용
1
2
CREATE INDEX CUSTOMER_ID_SERVICE_NAME_INDEX
ON CUSTOM_SERVICE(customer_id,service_name); # 복합 인덱스 생성
1
2
3
SELECT *
FROM CUSTOM_SERVICE as cs USE INDEX(CUSTOMER_ID_SERVICE_NAME_INDEX)
WHERE cs.customer_id = 9000 AND cs.service_name like '%:serviceName%';
LIKE ‘%:serviceName’케이스의 경우 조회된 행에 대해서 :serviceName 값이 포함되어 있는지 모두 확인해야하기 때문에 customer_id ,service_name 복합 인덱스는 의미가 없다. LIKE ‘:serviceName%’ 인 경우에 의미가 있을 수 있고 또한 customer_id 에 대해서 커스텀 서비스는 비교적 작은 수인 최대 100개 존재하기 때문에 복합 인덱스를 구성할 필요성이 없다고 생각한다.
옵티마이저
CUSTOMER_ID_SERVICE_NAME_INDEX , CUSTOMER_ID_INDEX 중에 옵티마이저는 CUSTOMER_ID_INDEX 를 사용하여 쿼리를 수행한다. 단 , LIKE ‘:serviceName%’인 경우에는 CUSTOMER_ID_SERVICE_NAME_INDEX 를 사용한다.
성능 비교
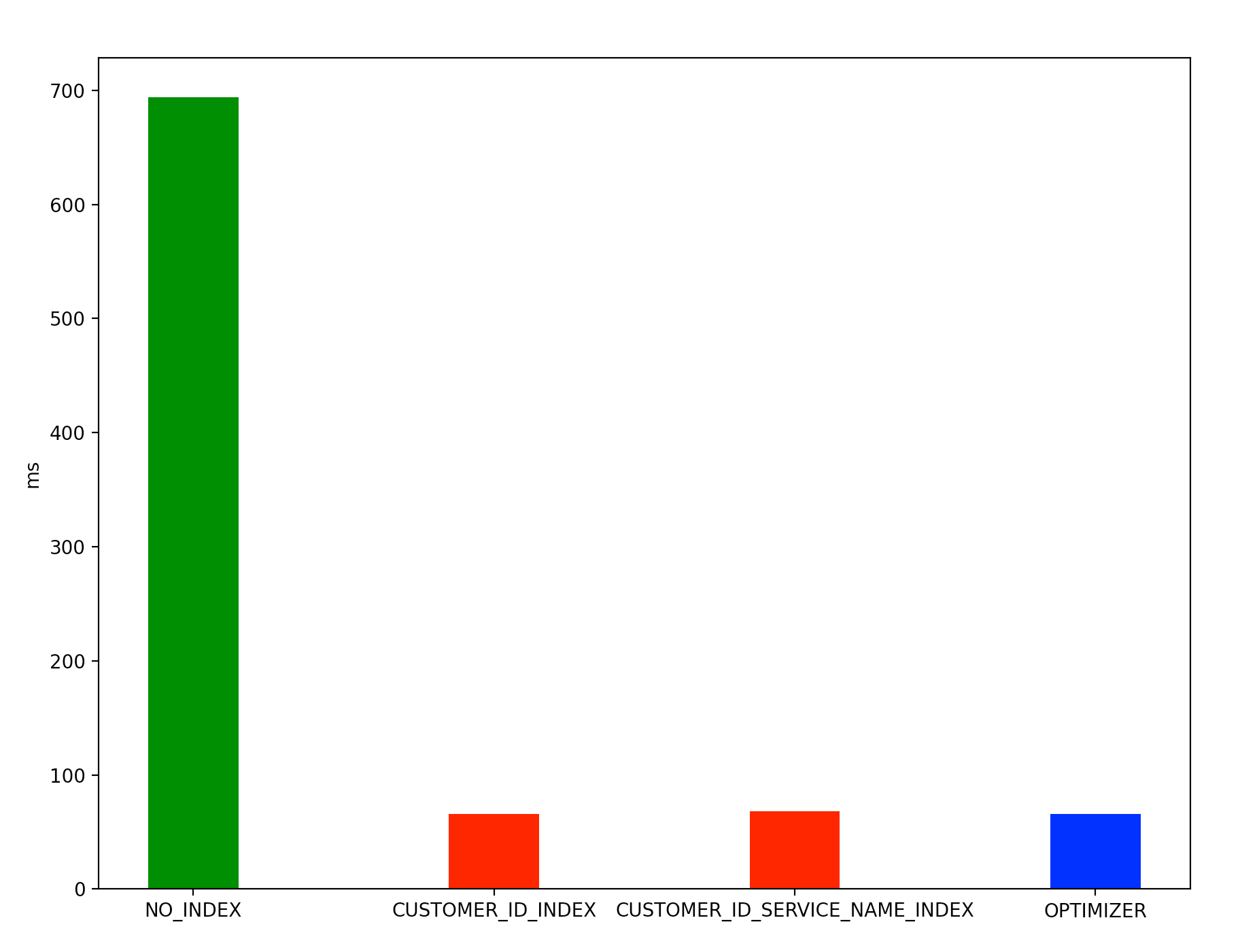
결론
두가지 쿼리를 분석해보았을 때 customer_id 를 인덱스 설정하면 인덱스를 설정하지 않았을 때 보다 약 10배 정도 조회 성능을 향상시킬 수 있었다. 사용자가 많아질 수록 커스텀 서비스 테이블 레코드 수가 증가할 것이고 이 때문에 특정 사용자는 등록한 커스텀 서비스가 많지 않음에도 불과하고 조회 쿼리가 1초가 넘어갈 수도 있었다. 하지만 customer_id 를 인덱스로 설정한 덕분에 사용자의 커스텀 서비스 조회는 자신이 등록한 커스텀 서비스 수에만 의존하게 되었다.
사용자 서비스 조회 쿼리 분석하기
사용자 서비스 조회의 경우 대부분의 쿼리가 앞의 커스텀 서비스 조회 쿼리와 비슷하다. 따라서 여러개의 service_id 가 주어졌을 때 이 중에서 사용자가 추가한 레코드를 조회하는 쿼리만을 분석한다.
쿼리
1
2
3
4
SELECT *
FROM customer_service cs
WHERE cs.customer_id = 10000
AND cs.service_id in(5,10,15,20,25,30);
인덱스 없이 조회하기
테이블 전체 접근으로 484 ms 가 소요된다.
service_id 인덱스 사용
1
CREATE INDEX SERVICE_ID_INDEX ON CUSTOMER_SERVICE(service_id); # service_id 인덱스 생성
1
2
3
4
EXPLAIN SELECT *
FROM customer_service cs USE INDEX(SERVICE_ID_INDEX)
WHERE cs.customer_id = 10000
AND cs.service_id in(5,10,15,20,25,30);
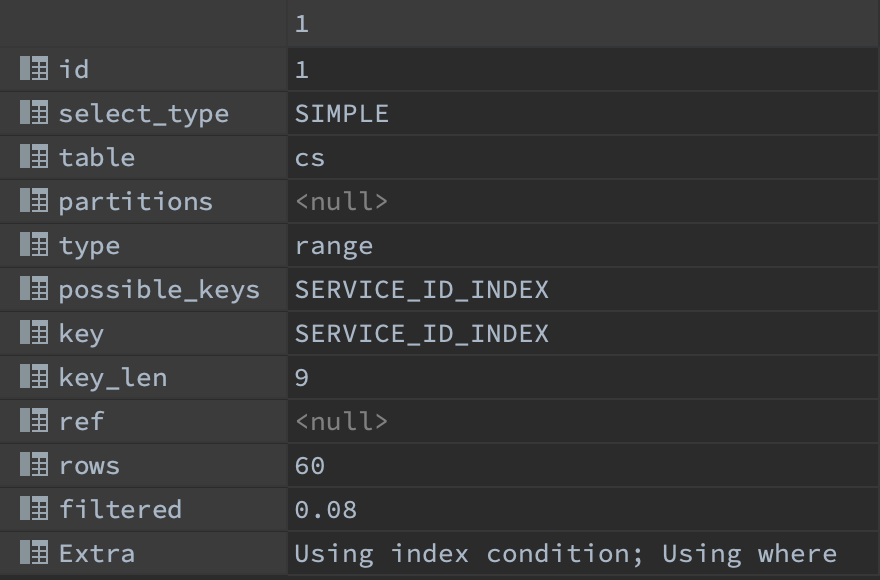
실행 계획을 보면 type 값이 range 로 service_id 인덱스 특정 범위의 행에 접근하고 customer_id 를 where 절로 최종 결과를 가져오는 것을 알 수 있다. 실제 수행시간이 60 ms 로 상당히 빠르게 동작한다. 하지만 service_id 인덱스를 사용한 이 쿼리에는 문제가 있다. in 쿼리에 service_id 가 많아졌을 때는 어떻게 될까? in 쿼리에 service_id 값이 많아질 수록 type 값이 range 가 type ALL에 근접해지는 문제가 발생한다.이는 service_id 인덱스로 조회 성능을 향상 시킬 수 없음을 의미한다.
customer_id 인덱스 사용
1
CREATE INDEX CUSTOMER_ID_INDEX ON CUSTOMER_SERVICE(customer_id); # customer_id 인덱스 생성
1
2
3
4
explain SELECT *
FROM customer_service cs USE INDEX(CUSTOMER_ID_INDEX)
WHERE cs.customer_id = 10000
AND cs.service_id in(SELECT * FROM SERVICES); # service_id 모두 조회
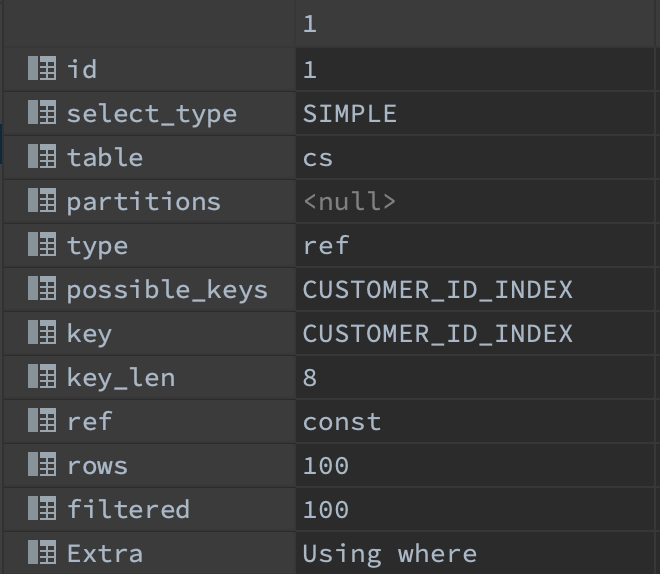
반면에 customer_id 를 인덱스로 설정했을 때 customer_id 인덱스를 먼저 수행한 뒤에 where 절로 최종 결과 값을 가져오기 때문에 service_id 수와는 크게 상관 없이 64ms 시간이 걸린다.
그렇다면 (customer_id. , service_id ) 복합 인덱스의 성능은 어떨까? 인덱스 동작 방식을 이해했다면 어느 정도 유추해 볼 수 있는데 customer_id 에 대한 service_id 값이 최대 100 개이기 때문에 그렇다 할 성능의 이점을 보지 못할 것으로 보인다.
옵티마이저
in 쿼리 안에 service_id 가 적을 경우 SERVICE_ID_INDEX 를 사용하지만 in 쿼리 안에 service_id 가 많은 경우 CUSTOMER_ID_INDEX 를 사용하는 것을 확인할 수 있었다.
성능 비교
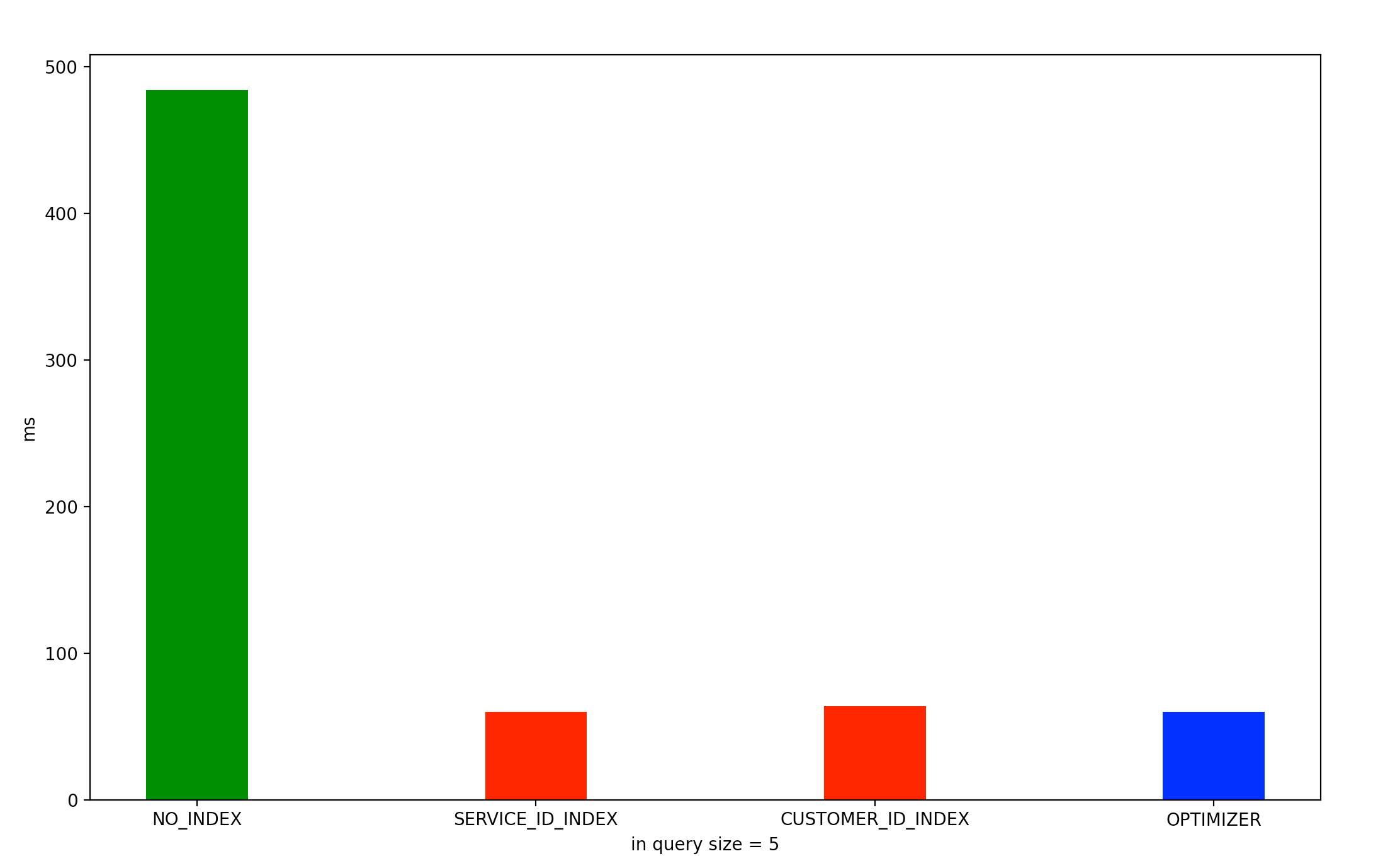
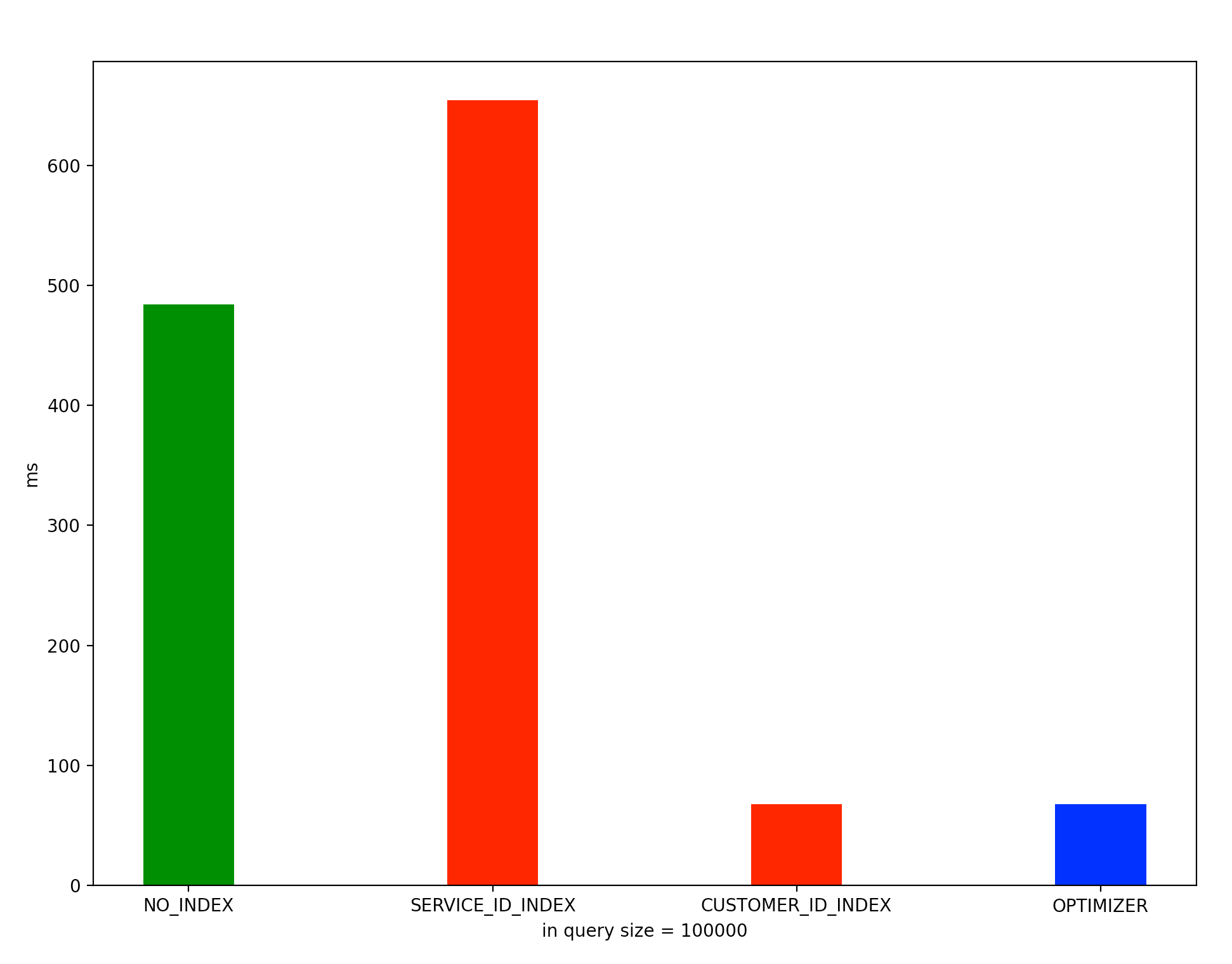
결론
결론은 결국에 customer_id 를 인덱스로 구성하는 것이 안정적인 성능을 얻을 수 있다는 것이다. 이는 사용자가 커스텀 서비스 , 서비스를 최대 100개씩 구성했다는 요구사항 때문이기도 하다. service_id 인덱스를 사용해도 특정 상황에 쿼리가 오래 발생할 수 있음을 인지하는 것이 중요하다.
마치며
웹 서비스가 10만개 , 사용자가 1만명 , 사용자마다 평균 100 개의 커스텀 서비스를 가지고 있고 100 개의 웹 서비스와 관계를 가지고 서비스를 이용한다는 가정에서 INDEX 를 설정하지 않았다면 사용자가 많아질 수록 사용자는 자신이 이용하고 있는 서비스들을 조회할 때마다 쿼리만 약 1초가 넘어가는 성능을 견뎌야했다.
하지만 알맞은 INDEX 를 설정함으로써 자신이 추가한 커스텀 혹은 사용자 서비스 수에만 의존하여 쿼리를 수행할 수 있었고 수치적으로 보았을 때 약 10배 이상의 성능을 얻었다.
한편으로는 INDEX 를 제대로 적용하지 않았을 시에는 INDEX를 설정한 것만 못한 성능이 나오기도 했었다.따라서 INDEX 를 적용하기 위해서는 데이터 분포도와 카디널리티를 고려하며 적용해야한다.